API design
API design is a complex topic that requires a lot of thought and consideration. In this section, we will discuss some best practices for API design and provide some tips for designing APIs that are easy to use and maintain. However, this is only a short introduction to the topic, complete books were written on the subject, and we recommend reading them for a more in-depth understanding of API design. One starting point may be the book "RESTful Web API Patterns & Practices Cookbook" by O'Reilly Media.
You also might want to look into existing API specifications like jsonapi.org to find some inspiration. Other useful resources are the OpenAPI and json-schema.org specifications.
The most important thing is, that before you start designing your API, sit down and think about what you want to achieve with it. Take into consideration the logic and restrictions of your backend systems too. Think about the data you want to expose and how you want to expose it. Consider the needs of your users and how they will interact with your API. Another important aspect is how your users will discover your API: through documentation, through cross-references provided in the responses, or through a service like Swagger.
Always try to establish conventions and stick to them. This will make your API more predictable and easier to use.
Large API providers like Google, Amazon, or Microsoft have their own API design guidelines. You might want to look into them for inspiration.
Some things to consider:
- How to name things? Use camelCase or snake_case?
- How to handle errors?
- What kinds of errors may occur?
- How to represent different kinds of errors?
- How to represent complex data structures?
- How to represent relationships between resources?
- How to handle list type responses, ordering and pagination?
When returning a response, your first idea may be to simply return the data as a single JSON object. Let's take simple example, a user:
{
"id": 1,
"name": "John Doe",
"email": "[email protected]"
}
Sometimes this is enough. But when your API gets more complex, you may want to add more information to the response. For example, you may want to include metadata about the returned entity. For a single object, this may be the type of the object and its canonical url. For example:
{
"meta": {
"type": "user",
"url": "/users/1"
},
"data": {
"id": 1,
"name": "John Doe",
"email": "[email protected]"
}
}
For a list of objects this may be the total number of items in a list, or the number of pages in a paginated response. You may also want to include links to related resources, or links to the next and previous pages in a paginated response. For example:
{
"meta": {
"total": 100,
"page": 1,
"per_page": 10
},
"data": [
{
"id": 1,
"name": "John Doe",
"email": "[email protected]"
}
],
"links": {
"self": "/users?page=1",
"next": "/users?page=2",
"prev": null
}
}
Limitations of JSON
One thing to be aware when working with JSON is that it has some limitations. First, the JavaScript number type is a 64-bit floating-point number, which limits the precision of integers to 53 bits. This means that integers larger than 2^53 cannot be represented accurately in JSON. This is not a problem for most use cases, but it is something to be aware of.
Some implementations of JSON parsers and serializers may allow integers larger than 2^53, but you cannot depend on this behavior.
If you need to represent large integers accurately, you may want to use a string representation instead of a number representation.
Dates and times
Date and time values have no specified representation in JSON. There are several ways to represent them, you should select one and stick to it.
The easiest way is to represent dates and times as strings, preferably in one of the ISO 8601 formats. This is the most widely used format for dates and times and is supported by most programming languages. For example a full date and time representation with second precision and timezone data would look like this:
"2021-05-01T18:20:00+02:00"
Be aware of timezones and daylight saving time when working with exact timestamps. They can be tricky to handle correctly. Errors may occur when converting between UTC and local time, especially when the local time is ambiguous due to daylight saving time changes.
For example, in the European Union, the time changes twice a year, in spring and autumn. In the spring, the time jumps forward by one hour, and in the autumn, it jumps back by one hour. This means that there is one hour that occurs twice in the autumn, and one hour that does not occur at all in the spring. The only ways to represent a point in time exactly is either in UTC or with a timezone offset that includes the information about the daylight saving time status too.
Null
This is not much of a problem in Rust, because Rust does not have a null
value just the Option type, so we are quite conscious about the absence of
a value.
But in JSON, null is a special value that represents the absence of a value.
So be always explicit about the fact that your API may return a null value
somewhere and document it accordingly.
When consuming an API, you should always check for null values and handle
them appropriately. This sometimes may be tricky, when the designer of the
API did forget to document the fact that a value may be null.
Stability
When designing an API, it is important to consider the stability of the API. Stability means that the API should not change unexpectedly, and that changes should be communicated to users in advance. This is especially important for public APIs, where changes can break existing clients.
One way to ensure stability is to use versioning. By versioning your API, you can make changes to the API without breaking existing clients. When you make a breaking change, you can release a new version of the API and allow clients to migrate to the new version at their own pace.
Another way to ensure stability is to use deprecation. When you deprecate a feature, you signal to users that the feature will be removed in a future version of the API. This gives users time to migrate to a new feature before the old feature is removed.
One technique for versioning is to include the version number in the URL.
For example, you could have URLs like /v1/users and /v2/users for
different versions of the API. This makes it easy for clients to switch
between versions by changing the URL.
An important thing to note: you usually do not break existing clients by adding new fields to a response, this is a safe way to extend your API without releasing a new version.
Documentation
If you write APIs that are used by others beyond you, those users have to learn somehow how to use your API. This is where documentation comes into play.
One way to document your API may be to simply write a text document that describes the API endpoints, the request and response formats, and the expected behavior of the API. This is a good start, but it is far more efficient to produce machine-readable documentation that can be used to generate human-readable documentation and client libraries automatically.
Basically, you have to describe:
- what endpoints are available
- which methods are available for each endpoint
- what parameters can be passed to each endpoint
- what can be expected in the response
There are two widely used formats for JSON API documentation: JSON Schema and OpenAPI. JSON Schema is a specification for describing the structure of JSON data, while OpenAPI is a specification for describing RESTful APIs. The two formats are mostly compatible, but there are some differences.
JSON Schema
JSON Schema is primarily used to describe the structure of the JSON objects sent and received in the body of HTTP requests and responses. One implementation of JSON schema is the schemars crate for Rust. It is quite simple to use:
#[derive(JsonSchema)]
pub enum PostStatus {
Draft = 1,
Published = 2,
}
#[derive(JsonSchema)]
pub struct Post {
pub id: i64,
pub author_id: i64,
pub slug: String,
pub title: String,
pub content: String,
pub status: PostStatus,
pub created: DateTime<Utc>,
pub updated: DateTime<Utc>,
}
let schema = schema_for!(Post);
println!("{}", serde_json::to_string_pretty(&schema).unwrap());
The JsonSchema macro provides a way to automatically build a JSON schema
from a Rust data structure. The schema_for! macro generates the actual
JSON representation of the schema that can be shared with the consumers of
your API.
The actual schema looks like this:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Post",
"type": "object",
"required": [
"author_id",
"content",
"created",
"id",
"slug",
"status",
"title",
"updated"
],
"properties": {
"author_id": {
"type": "integer",
"format": "int64"
},
"content": {
"type": "string"
},
"created": {
"type": "string",
"format": "date-time"
},
"id": {
"type": "integer",
"format": "int64"
},
"slug": {
"type": "string"
},
"status": {
"$ref": "#/definitions/PostStatus"
},
"title": {
"type": "string"
},
"updated": {
"type": "string",
"format": "date-time"
}
},
"definitions": {
"PostStatus": {
"type": "string",
"enum": [
"Draft",
"Published"
]
}
}
}
As you can see, the schema describes the structure of the Post data structure
and the PostStatus enum. The schema includes information about the required
fields, the types of the fields, and any constraints on the fields.
You can use this schema to validate JSON data against the schema. For example, when you deserialize JSON POST data from an HTTP request, you can validate the data against the schema to ensure that it conforms to the expected structure and return appropriate error messages if it does not. This is much more informative than simply returning a "deserialization failed" message.
When working with a remote API as a consumer, you can use the JSON Schema to
generate client code that can serialize into API requests or deserialize
from API responses. This can save you a lot
of time and effort, as you do not have to write the client code manually.
Also, you can validate each response you receive from the API to ensure that
it conforms
to the expected structure. For example, when an attribute is not optional, but
the API returns it as null, you can raise an error.
Browser-based consumers of your API can use the JSON Schema to generate TypeScript types and zod schemas to validate the data they receive from your API. TypeScript also enables autocomplete for the attribute names in most IDEs, making the life of frontend developers easier.
OpenAPI
OpenAPI is a specification for describing RESTful APIs. It is more complex than JSON Schema. OpenAPI can describe not only the structure of the JSON data sent and received in the body of HTTP requests and responses, but also the structure of the HTTP requests and responses themselves. This includes the HTTP method, the URL path, the query parameters, the request headers, the response status codes, and the response headers.
OpenAPI describes the structure of the API in a machine-readable format that can be used to generate human-readable documentation and client libraries automatically. The format is a JSON file, something like this:
{
"openapi": "3.0.3",
"info": {
"title": "cli_app",
"description": "",
"license": {
"name": ""
},
"version": "0.1.0"
},
"servers": [
{
"url": "/v1",
"description": "Local server"
}
],
"paths": {
"/hello": {
"get": {
"tags": [
"hello"
],
"operationId": "hello",
"responses": {
"200": {
"description": "Hello World",
"content": {
"text/plain": {
"schema": {
"type": "string"
}
}
}
}
}
}
}
},
"components": {
"schemas": {}
},
"tags": [
{
"name": "hello",
"description": "Hello"
}
]
}
This OpenAPI file describes a simple API with a single endpoint /hello.
The endpoint responds to a GET request with a 200 status code and a
text/plain content type. The response body is a string.
To generate this file, we can use the utoipa create.
We can describe a single endpoint like this one in
src/api/handlers/helpers.rs:
use crate::state::ApplicationState;
use axum::extract::State;
use axum::http::StatusCode;
use std::sync::Arc;
#[utoipa::path(
get,
path = "/hello",
tag = "hello",
responses(
(status = 200, description = "Hello World", body = String),
),
)]
pub async fn hello(State(state): State<Arc<ApplicationState>>)
-> Result<String, StatusCode> {
Ok(format!(
"\nHello world! Using configuration from {}\n\n",
state
.settings
.load()
.config
.location
.clone()
.unwrap_or("[nowhere]".to_string())
))
}
The utoipa::path macro defines an endpoint in the OpenAPI format.
First we indicate that this endpoint uses the GET method and is located
at /hello. We also tag this endpoint with the hello tag (so we can group
the endpoints later). The responses attribute defines the possible responses
of the endpoint. In this case, we only have one response, with a status code
of 200, a description of "Hello World", and a body of type String.
To build the OpenAPI spec of the whole application, we create a struct in
src/api/v1.rs and add the #[derive(OpenApi)] macro to it:
#[derive(OpenApi)]
#[openapi(
paths(
handlers::hello::hello,
),
components(
schemas(
),
),
tags(
(name = "hello", description = "Hello"),
),
servers(
(url = "/v1", description = "Local server"),
),
)]
pub struct ApiDoc;
First we list the documented endpoints in the paths attribute. Then we
list the tags we used in the tags attribute. We also define the server
available for API testing in the servers attribute. The components
attribute is used to define reusable components like schemas, but we do not
have any in this example.
Finally, in src/api/mod.rs we add the following snippet to generate the
OpenAPI specification and a
Swagger UI at the same time:
pub fn configure(state: Arc<ApplicationState>) -> Router {
Router::new()
.merge(SwaggerUi::new("/swagger-ui").url(
"/v1/api-docs/openapi.json",
crate::api::v1::ApiDoc::openapi(),
))
.nest("/v1", v1::configure(state))
}
For the above code to work, we have to add the following dependencies to our
Cargo.toml:
[dependencies]
utoipa = { version = "4.2.0", features = ["axum_extras", "chrono"] }
utoipa-swagger-ui = { version = "6", features = ["axum"] }
After building and starting the application, you can access the Swagger UI at
http://127.0.0.1:8080/swagger-ui and the OpenAPI specification at
http://127.0.0.1:8080/v1/api-docs/openapi.json.
The UI will look like this:
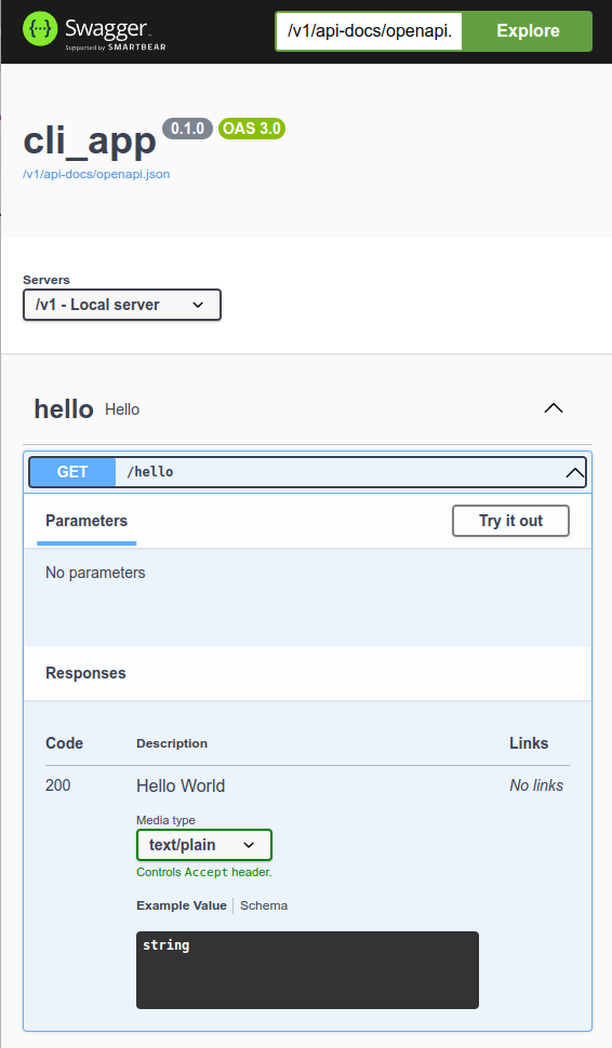 .
.
Now we can document more complex endpoints, like the create post endpoint
in src/api/handlers/posts.rs:
#[utoipa::path(
post,
path = "/posts",
tag = "posts",
request_body = CreatePostRequest,
responses(
(status = 200, description = "Post create", body = SinglePostResponse),
),
)]
pub async fn create(
Extension(_claims): Extension<TokenClaims>,
State(state): State<Arc<ApplicationState>>,
Json(payload): Json<CreatePostRequest>,
) -> Result<Json<SinglePostResponse>, AppError> {
let post = state.post_service.create_post(payload).await?;
let response = SinglePostResponse { data: post };
Ok(Json(response))
}
This endpoint uses the POST method and is located at /posts. The request
body is defined by the CreatePostRequest struct. The response is a 200
status code with a body of type SinglePostResponse.
We did not document these structs for OpenAPI yet. To do so, we will use
the utoipa::ToSchema derive macro:
use utoipa::ToSchema;
#[derive(Deserialize, ToSchema)]
pub struct CreatePostRequest {
pub author_id: i64,
pub slug: String,
pub title: String,
pub content: String,
pub status: PostStatus,
}
The macro can automatically generate the JSON schema for basic types like
i64, String, but for our own types like PostStatus we have to implement
the ToSchema trait for ourselves by adding the ToSchema derive macro there
too:
#[derive(Copy, Clone, Serialize, Deserialize, ToSchema)]
pub enum PostStatus {
Draft = 1,
Published = 2,
}
We have to repeat the same with the SinglePostResponse struct, and with
all the types it references.
After that, we can add our new endpoint and all the referenced types to the
ApiDoc struct in src/api/v1.rs:
#[derive(OpenApi)]
#[openapi(
paths(
handlers::hello::hello,
handlers::posts::create,
),
components(
schemas(
crate::services::post::CreatePostRequest,
crate::api::response::posts::SinglePostResponse,
crate::model::Post,
crate::model::PostStatus,
),
),
tags(
(name = "hello", description = "Hello"),
(name = "posts", description = "Posts"),
),
servers(
(url = "/v1", description = "Local server"),
),
)]
pub struct ApiDoc;
We can use OpenAPI to describe path parameters as well:
#[utoipa::path(
put,
path = "/posts/{id}",
params(
("id" = i64, Path, description = "ID of the post"),
),
tag = "posts",
request_body = UpdatePostRequest,
responses(
(status = 200, description = "Post updates", body = SinglePostResponse),
),
)]
pub async fn update() {
// ...
}
Here we specify that the id parameter is a path parameter of type i64.
We can also describe query parameters in a similar way:
use utoipa::{IntoParams, ToSchema};
#[derive(Deserialize, Debug, IntoParams)]
#[into_params(parameter_in = Query)]
pub struct PagingParams {
/// Page number
pub page: i64,
/// Items per page
pub per_page: i64,
}
#[utoipa::path(
get,
path = "/posts",
params(PagingParams),
tag = "posts",
responses(
(status = 200, description = "Posts list", body = PostsListResponse),
),
)]
pub async fn list() {
// ...
}
You can find the sample codes on GitHub
TBD:
- schemars